Player matching is a critical aspect of multiplayer games, as it ensures that players are matched with opponents of similar skill levels, providing a fair and enjoyable gameplay experience.
Recently I had the opportunity to work on the backend services of an online game where two players can mount a deck of summonable creatures and fight against each other in real time on their mobile devices. The game is fun and as the user base begins to grow a problem arises: how can we join two players in a fair fight?
Imagine that we have, at a given moment, 1200 players searching for an opponent to fight. Some of them may have 10 hours of gaming while others may have 200 hours. Some are in early levels, others, way more advanced. Some may have a long stream of wins while others barely win a couple of fights. How do we measure who is a good opponent to who?
The KNN Algorithm
The K-Nearest Neighbors (KNN) is, probably, one of the first algorithms we learn when studying machine learning or applied statistics due to its simplicity and easy-to-grasp concepts. It is a distance-based machine-learning algorithm because it relies on the idea that related data should appear in the same region so, if two samples have a correlation, they should appear near each other in their projected space.
Look at the graphics:
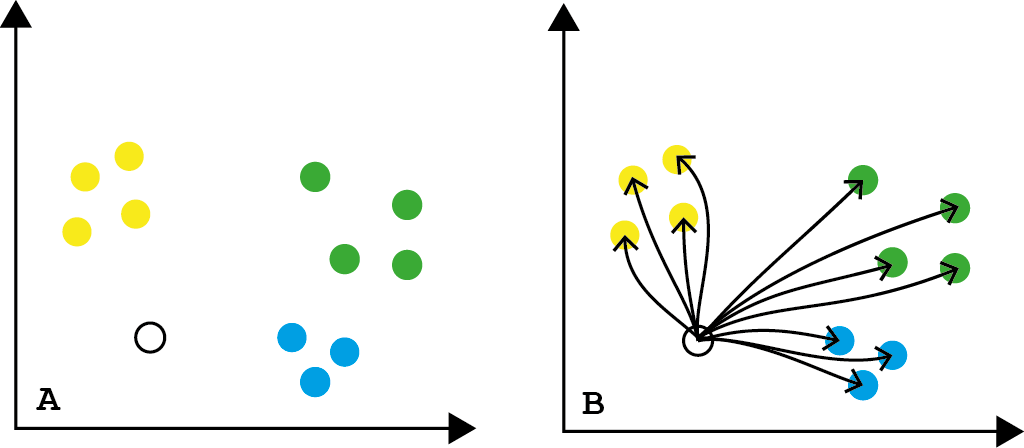
On the left graphic, there are 3 classes: yellow, green, and blue. We also have an unknown class point, represented by the white color, which we wish to classify based on the probability that it pertains to one of their “neighbor” classes.
To achieve that, we calculate the distance between the white point to all the other points in the population as exemplified in the right image, and then choose the k nearest points. If k=3, for example, we have 2 yellow points and 1 blue point selected, so there is a 66,6% of chance that this point is of yellow class, and… that’s it. This is the basic idea of the K-Nearest Neighbors (KNN) algorithm. Really! It’s just that.
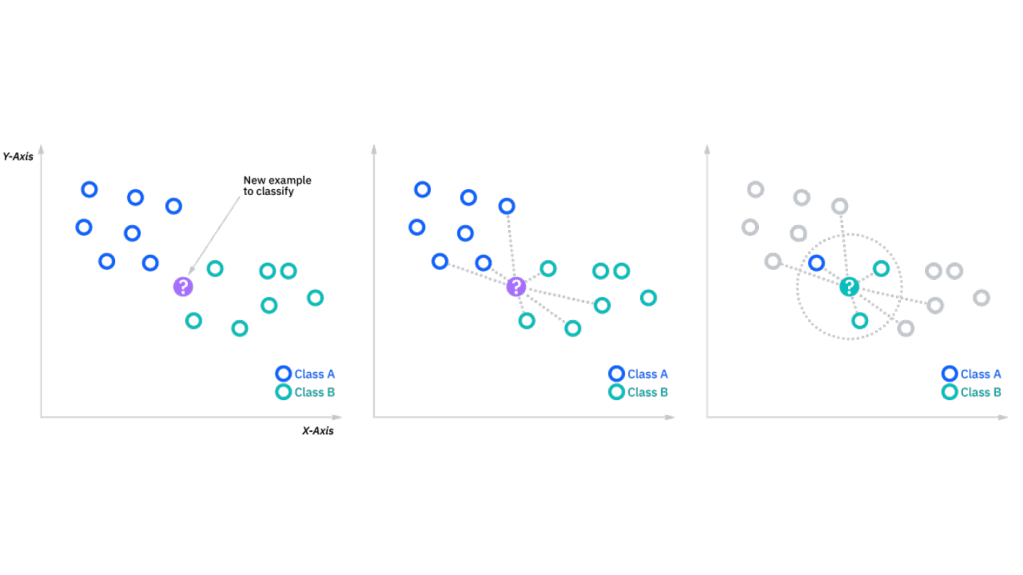
You can see the three steps illustrated in the following graphics:
Applying it!
So, the problem to solve is to choose a fair opponent for a given player among the universe of online players. I can’t publish real data here, but we can simulate and illustrate the problem with our own generated data. So let’s start with basic data creation on SQLServer.
if (object_id('tempdb..#PlayerData') is not null)
drop table #PlayerData
create table #PlayerData (
PlayerID int primary key identity,
WinLossRatio float,
Accuracy float,
PingTimeMS int,
)
-- create a population of 100,000 random players
declare @i int = 1
while @i <= 100000
begin
insert into #PlayerData (WinLossRatio, Accuracy, PingTimeMS)
values (rand(), rand(), round(rand()*1000, 0))
set @i = @i + 1
end
select top 5 * from #PlayerData
Output:
| PlayerID | WinLossRatio | Accuracy | PingTimeMS |
|---|---|---|---|
| 1 | 0,907362409918751 | 0,796193089617112 | 59 |
| 2 | 0,415995706035458 | 0,737326135001008 | 374 |
| 3 | 0,006123595106616 | 0,502084640966905 | 873 |
| 4 | 0,167724872854256 | 0,375710986550611 | 906 |
| 5 | 0,0498535991264818 | 0,236891712930946 | 996 |
Good! We have a PlayerData table with 100,000 random players and 3 relevant attributes: WinLossRatio, Accuracy, and PingTimeMS.
While the first two are related to the player’s in-game performance, we also have available on our database, the last known user’s ping information. This is pretty useful to move away players with bad connection conditions and to show that we can do multi-dimensional projections on KNN implementation.
Calculating Distances
There are several distance calculations we can use with distance-based machine learning algorithms. We’ll stick with the most common: the Euclidean distance. So:
/*
we should normalize the PingTimeMS data to the (0..1) range, considering
the max(PingTimeMS) as the limit, so lets store it in @MaxPingTimeMS
*/
declare @MaxPingTimeMS float = (select max(PingTimeMS) FROM #PlayerData)
declare @k int = 3 /* K hyper parameter of KNN */
declare @TargetPlayerID int = 1
-- query to find the K-nearest neighbors of the TargetPlayerID
select top (@K) WITH TIES
player.PlayerID,
player.WinLossRatio,
player.Accuracy,
(player.PingTimeMS / @MaxPingTimeMS) NormalizedPing,
/* euclidean distance between attributes */
sqrt(
power(player.WinLossRatio - opponent.WinLossRatio, 2) +
power(player.Accuracy - opponent.Accuracy, 2) +
power(
(player.PingTimeMS / @MaxPingTimeMS) -
(opponent.PingTimeMS / @MaxPingTimeMS), 2)
) AS Distance
from #PlayerData as player,
(select * from #PlayerData
where PlayerID <> @TargetPlayerID) as opponent
where player.PlayerID = @TargetPlayerID
and player.PingTimeMS < 400 /* minimum acceptable latency */
order by Distance
Output:
| PlayerID | WinLossRatio | Accuracy | Ping | Distance |
|---|---|---|---|---|
33765 |
0,9146020009807 |
0,7903267476986 |
0,053 |
0,0110826732446677 |
| 28785 | 0,9161540072527 | 0,7929262921270 | 0,048 | 0,0144555923270013 |
| 17993 | 0,9177007361853 | 0,7932708847486 | 0,071 | 0,0161065288404087 |
Bingo! We had, with a single query, calculated the K better fits for a @TargetPlayerID player fight considering all the 3 selected opponents’ attributes using machine learning techniques! We can generalize this query in a stored procedure and execute it from the backend controller code inside a REST API endpoint and consume it on our devices.

Considerations
This is, obviously, a pretty naive implementation with the purpose of exemplifying how we could rapidly implement and test machine learning techniques in this scenario. The KNN is known for its poor performance with large datasets but, if we can keep our problem’s population short enough, and choose wisely the attributes, we can use KNN for near real-time match-making in online gaming.
On the project where we test this idea, we have around 2,500,000 fights per day, ~60..80 fights starting per second on peaks and the database server barely reaches 30% of CPU load which means we can still support a good amount of player base increase before we reach the hardware limit.
Keep it simple, stupid, they say!
